
前言
本文关注的重点是语音识别的硬件载体:语音识别芯片,特别是离线语音识别芯片。
一、 语音识别技术的原理
定义:语音识别技术(ASR Automatic SpeechRecognition),让智能设备听懂人类的语音。语音识别的工作流程,可以分为三大步骤:前端语音处理、模型训练、后端识别处理。
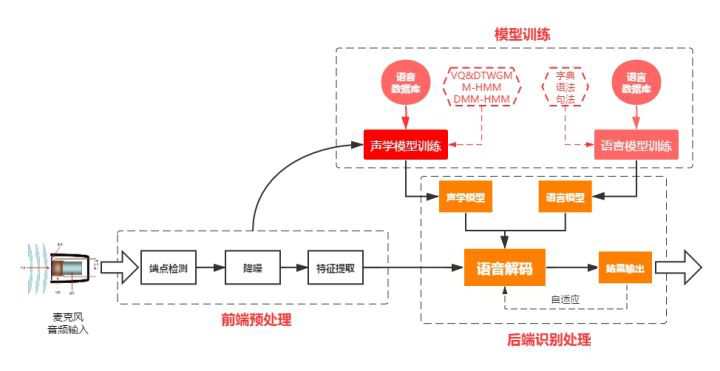
1.前端处理
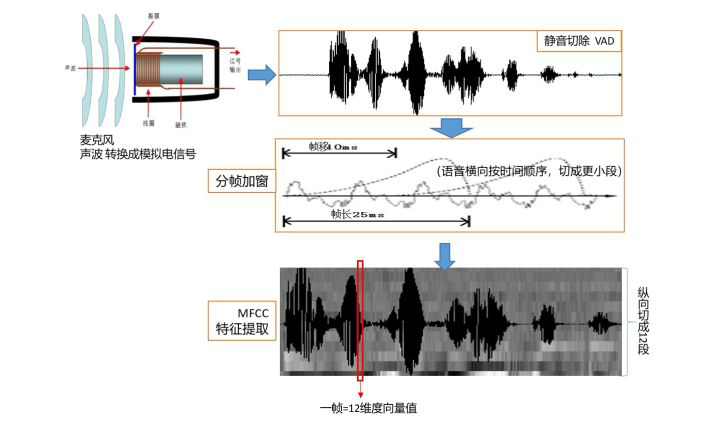
前端处理,即将语音的模拟信号,转换成机器能读懂的数字信号,并做信号优化处理。前端处理关联硬件:麦克风、Codec/ADC、PDM\I2S、音频处理能力(NPU或DSP)以下是前端处理的流程原理简化:
语音声波转模拟电信号:麦克风分柱极体和硅麦两种,硅麦又分为模拟和数字。
预处理: 静音切除 VAD、分侦加窗、降噪(主动降噪ANC)、预加重等。
特征提取:图中选的是主流的MFCC,其他还有LPCC,PLP等,选取后续可以匹配的特征点。
2.模型训练
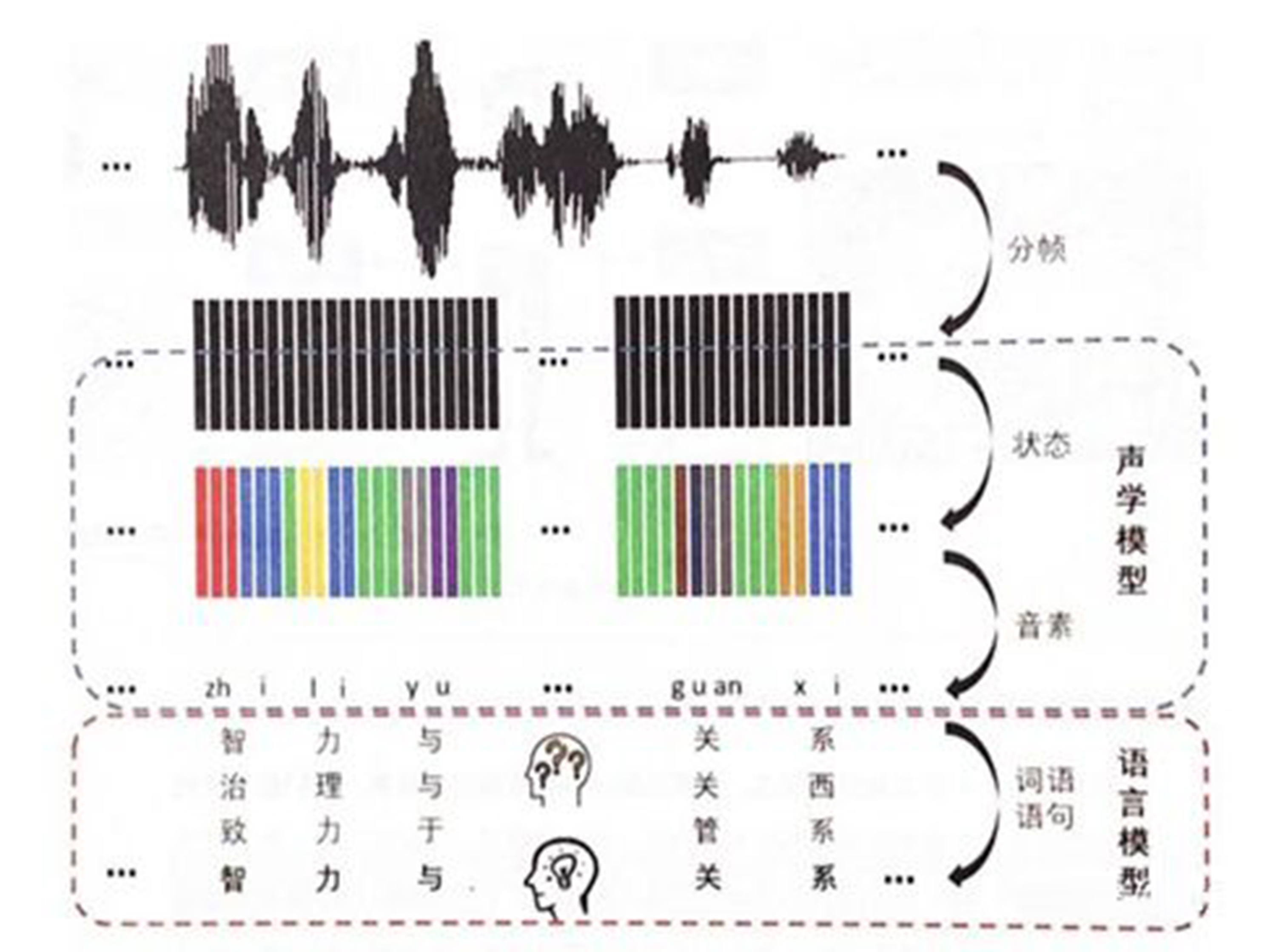
模型 可以理解为“字典”,机器收到语音信息后,跟模型比对找出相似的语音和单词。
那模板怎么来的呢?这需要通过预先大量地采集语音和语言信息(通常叫语料收集),并通过特定的算法跳出最典型的语音特征值。这就叫做“模板训练”,编辑一本字典出来。语音识别系统的模型训练通常分为两套:
语言模型训练:语言模型是用来计算一个句子出现概率的概率模型,是语音识别中的”字典”它需要综合三个层次的知识:字典,语法,句法,让机器能更好理解人类的自然语言。
声学模型训练:声学模型是识别系统的底层模型,是语音识别系统中最关键的部分,算法主要集中优化该部分声学模型是通过大量的语音收集,并根据特定的算法规则获得特征值,用于后面的识别比对。互联网巨头,拥有大量的用户基数和语音收集渠道,相对于传统公司有优势。
3.后端识别处理(语音解码)
指利用训练好的“声学模型”和“语言模型”对提取到的特征向量进行识别,并输出识别结果。该步骤跟模型建立有深度关联,有时将”模型建立”归类到后端识别处理中,与前端处理对应。
识别准确率和响应速度,通常取决于主控运算速度,以及前端处理和模型的综合表现。
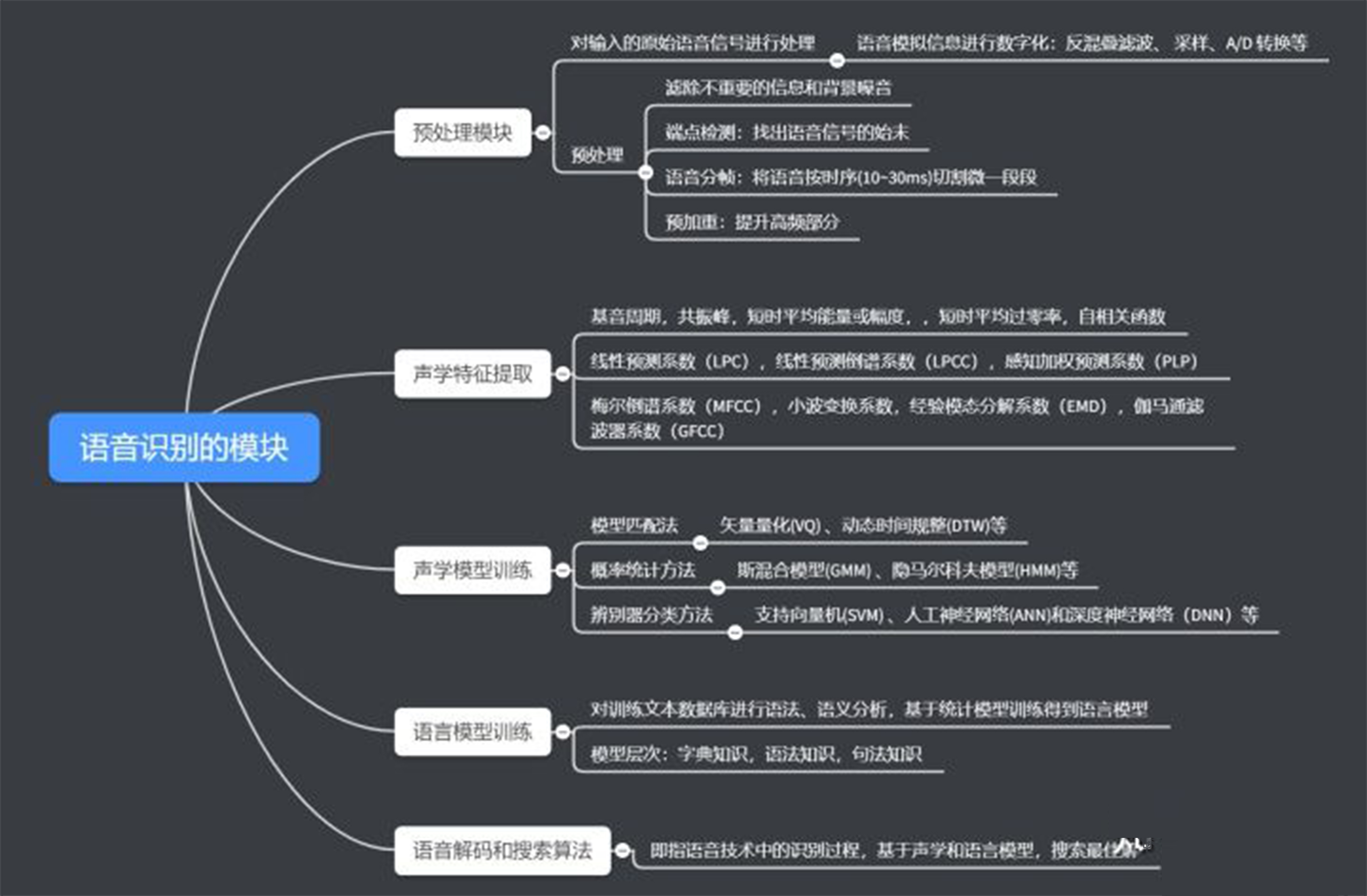
以下是详细语音识别技术的原理分支整理:
二、语音识别技术的发展史
鉴于语音识别芯片,是与算法有着高度关联。所以以下简单探讨了语音识别技术的发展史。
语音识别技术的核心和发展,主要在声学模型的建模(训练)的领域上,可以分为三个阶段:
第一阶段 模型匹配法 / 语音标签(70年代)
主要集中在小词汇量、孤立词、特定人语音识别方法,方法是简单的模板匹配
模板匹配:测试语音与参考语音 分别进行特征值提取后,直接整段比对吻合度。
主流算法:动态时间规整(DTW)、支持向量机(SVM)、矢量量化(VQ)。
技术局限:同个人感冒就识别不了,匹配方法原始,命令词多了识别效率很慢。
第二阶段:概率统计型(1993年~2009年)
部分厂家称为非特定人语音识别,准确来说是概率统计型,主流的技术是GMM+HMM。
HMM模型将语音转换文本的过程中,增加了两个转换单位:音素和状态
GMM 是将状态的特征分部,用概率模型来表述,提升语音帧到状态的准确率。
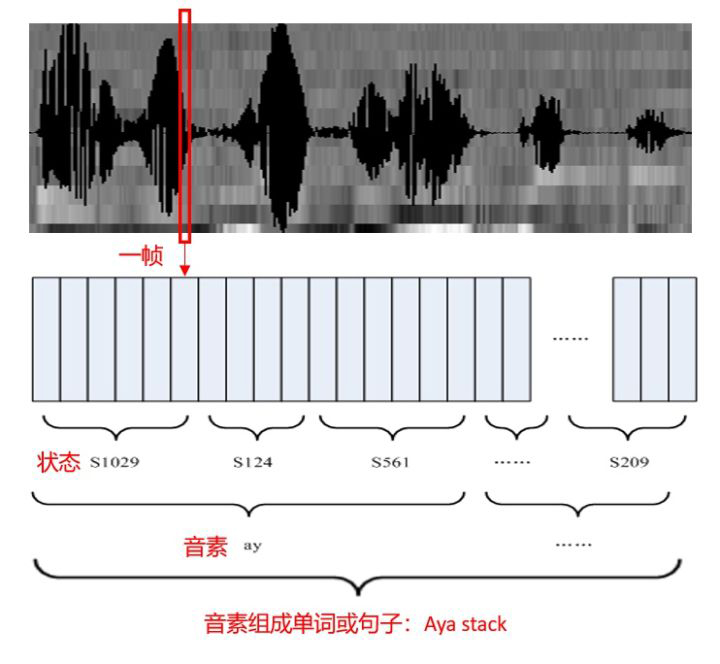 基于GMM-HMM框架,后续又提出了许多改进方法:动态贝叶斯方法、区分性训练方法自适应训练方法、HMM/NN混合模型方法等 GMM+HMM模型,在大词汇量的语音识别情况下,识别准确率和效率均比较c差。
基于GMM-HMM框架,后续又提出了许多改进方法:动态贝叶斯方法、区分性训练方法自适应训练方法、HMM/NN混合模型方法等 GMM+HMM模型,在大词汇量的语音识别情况下,识别准确率和效率均比较c差。
第三阶段:辨别器分类方法(2009年至今)
常被成为深度神经网络识别,是当下最主流语音识别技术类型,包括:
2、递归神经网络RNN——>LSTM&BLSTM:结合上下文建模,计算复杂度会比DNN增加。3、卷积神经网络CNN:图像识别的主流的模型,优化语音的多样性,减少硬件资源浪费。
下一代语音识别技术:端到端CTC?
不再需要HMM来描述音素内部状态的变化,而将语音识别的所有模块统一成神经网络模型。国内大厂的技术选择:科大讯飞–深度全序列卷积神经网络DFCNN)、阿里LFR-DFSMN、
百度SMLTA、Kaldi。
三、语音识别芯片的比对
按照语音识别的市场应用的发展方向,我们可以将语音识别芯片分为两大类:
在线语音识别:即大词汇量连续语音识别系统
典型应用:在线翻译、智能客服、大数据分析、服务机器人等。
离线语音识别:即小词汇量、低功耗、低成本的语音识别系统。
典型应用:智能家电、语音遥控器、智能玩具、车载声控、智能家居等。
离线和在线的区别在于:语音识别的工作是放在本地设备端还是云端服务器。
在线语音识别芯片:
在线语音芯片只做前端语音处理,后端识别处理都放在云端服务器,所以才称为在线。在线语音识别芯片,严格来说定义也不大对了,它更像个”万精油”型的芯片。芯片配置强大的CPU、大容量存储、完整的音视频和通讯接口,甚至会内置PMU、WiFi、PHY等功能。它可以被应用于语音识别,也可以应用于其他多媒体的处理,是个万精油型的主控芯片。所以该类别的厂商,通常都是像的MTK、瑞芯微、全志这类最早做平板和手机CPU的。
该类芯片包括:士兰微和阿里合作的SC5864、全志与科大讯飞合作的R16和XR872、瑞芯微 RK2108、MTK MT8516、炬芯ATS3605D等,典型的应用就是智能音箱。
(注:本文关注重点是离线语音识别,在线的就不展开详细叙述和对比了。)
离线语音识别芯片
根据前两个篇章的内容,结合公司背景等因素,我将语音识别芯片分类如下:

芯片比对参数说明:
识别距离&识别率:属于芯片的两个重要显性指标,与消费者的体验直接相关,但由于每家厂商测试的前提条件各自不同,也跟芯片的市场定位有关,所以并非绝对指标。
处理器:分为MCU和Audio Core,前者偏芯片与周边期间协同合作的控制器,后者偏处理音频信号和跑识别算法,后者相对于前者更重要些,是直接决定芯片的语音识别的响应速度和准确率的重要因素。
存储:硬件存储决定了处理器可调用的资源大小,也决定了识别词条数量
语音算法:分前端信号处理算法(降噪\波束成形\回应消除\VAD静音抑制\麦克风矩阵\远场识别等)和后端识别算法(声学模型算法/NPL自然语言等)。这个是偏软的参数
音频通道&外设接口: 芯片与周边器件的通信桥梁,对于语音识别来说,音频的输入和输出更重要,单独提列出来。音频输入分模拟输入(ADC)和数字输入(PDM),音频输出通常是DAC。
电源功耗:功耗不能直接比对大小,而是要比能耗比,即同样性能下的功耗对比。
其他因素:工作温度、封装等,以及特殊备注。
以上参数,除了通用的硬件参数,其余的各家定义也略微有些不同,不能单独对比。
1.0&2.0时代:传统型
算法模型主流是GMM+HMM,或者模型匹配(语音标签)的。而且,由于芯片配置简单,不具备降噪等功能,识别距离在2~5m,识别率通常在90%左右。词条数5~10条。
每家的芯片有基本的ASR功能,但各自都有”性能短板”:不带主控、不带存储、语音指令和算法外挂、OTP固定词条、性能低端、接口单一等等,这些短板,都是为了降低成本,在低端市场需要有成本优势。
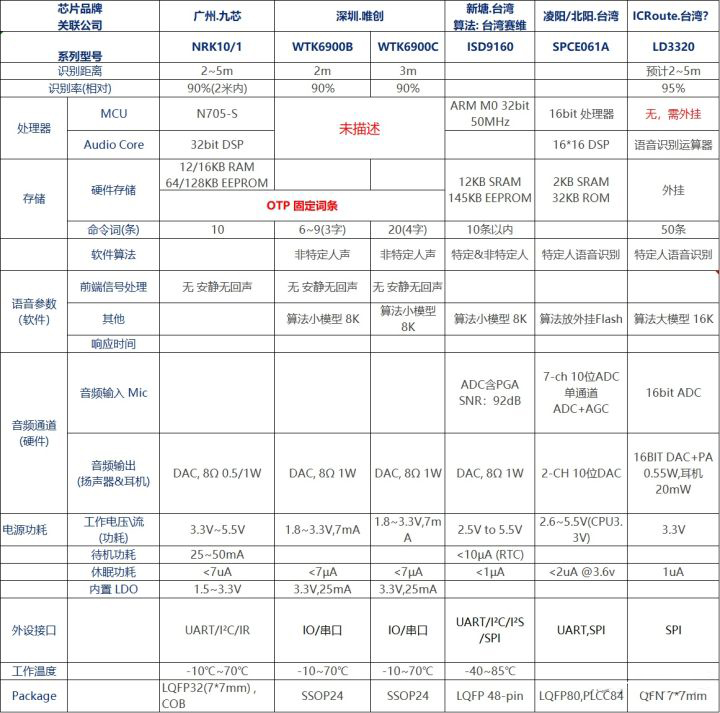
台湾系早几年前曾是离线语音识别领域最活跃的,包括芯片厂新塘和凌阳,以及台湾赛维这类算法公司。本人就曾推广过新塘ISD9160,当时在家电领域应用挺多,但因识别率差等原因,消费市场反馈差,需求下滑很快。
都是曾经非常通用的语音识别芯片,有现成的动态指令库,开发简单好用。
ICRoute 上海音航
根据以上表格,这家公司的LD3320除了没有MCU,其余语音识别功能都比较完整,所以识别率达到95%和命令词50条。再看其官网(http://www.icroute.com/) 的开发资源和技术介绍非常完整,也有方便用户定制指令的软件工具。如果不考虑价格,个人感觉他们家在传统型中,应该算是最棒的。
另外,该公司的大股东孙放,也是北京雷动云合的联合创始人,雷动云合是做视觉识别产品的。果然,大佬们都盯着未来AI人机的两大入口:视觉 & 语音识别。
广州九芯\深圳唯创
除了语音识别,都有做语音芯片(常见于儿童玩具),在网上很活跃,成本应该很低。
同类的还有深圳盛矽和深圳捷通等,都是集中在广东区域啊,广东的汕头澄海盛产的玩具产品等可是遍及全球呢,产业的发达果然是能带动起周边相关行业的发展啊。
3.0时代:互联网型
互联网公司最近几年纷纷活跃于互联网行业之外,寻找新的增长点或加深企业护城河纵深。语音识别和视觉识别作为人机交互两大入口,自然也就得到互联网企业的青睐。但互联网公司自身没有芯片设计能力,往往需要借助外力,战略合作和\收购控股\购买成熟IP等是常见手段。
互联网公司推出的语音识别芯片,纷纷专注于用上高配置的DSP(功耗自然不低),而且拥有丰富的外设接口,芯片可以实现离在线一体化的功能。主要技术特点侧重于后端识别算法,但前端信号处理能力也不弱。
互联网型还有个广为人知的特点,以低价杀穿市场,快速获取用户增长。这个我们看在近年来互联网行业大规模烧钱竞争即可知。只是我个人觉得,所谓的互联网思维对于需要长周期精耕细作的芯片行业来说,是否利大于弊还是搞乱一锅粥大家都挨饿?
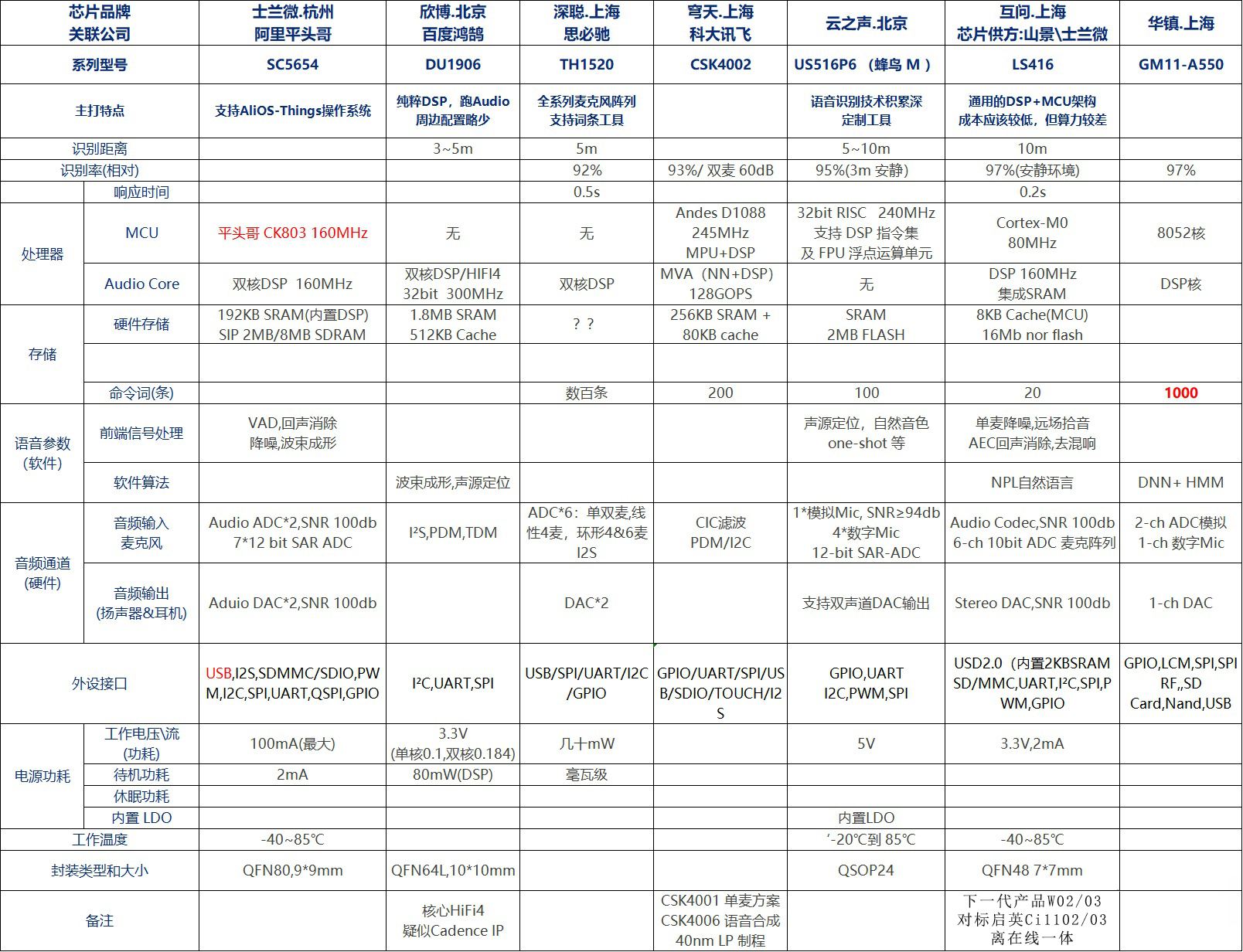
厂商分析:
互联网巨头:阿里巴巴和百度
两家互联网巨头本身都有各自成功的智能音箱产品:天猫精灵和小度,各自也分别选择多家芯片原厂合作推出在线和离线芯片,实现自产自销。阿里平头哥 将IP卖给合作公司,百度则是购买Candence HiFi4 IP(话说这个IP最近看了至少有三家在用或即将用)
在线语音识别巨头:讯飞、思必驰、云之声
三家在线语音识别巨头,纷纷从云端幕后往前台站出来,将已有的语音识别算法技术优势,进一步下沉到端侧的离线语音识别芯片,打通线上和线下。三家各自市场侧重点都不同,讯飞侧重教育行业、思必驰侧重车载行业、云之声侧重家电行业,当然这个划分也非绝对,各自肯定有交叉竞争关系。
语音算法公司:互问、华镇
相比讯飞等三家,互问和华镇的技术更”硬”一些,技术也更偏硬件侧。两家各自都找第三方芯片公司,合作推出自家命名的芯片产品。
3.0时代:纯芯片型
纯芯片型大部分属于初创新公司,拥有完整得芯片设计到算法开发的能力,相比于传统型,纯芯片型算法技术更优;相比于互联网型,纯芯片型更专注芯片硬件技术。
芯片语音处理核心,多为专用的NPU。同等资源下,NPU算力和能耗比远高于通用DSP。而且该类芯片多具有强大的前端信号处理能力,能真正做到降噪\原唱识别等功能。加上不断优化的声学算法模型和语料定制,识别率通常在95%以上。
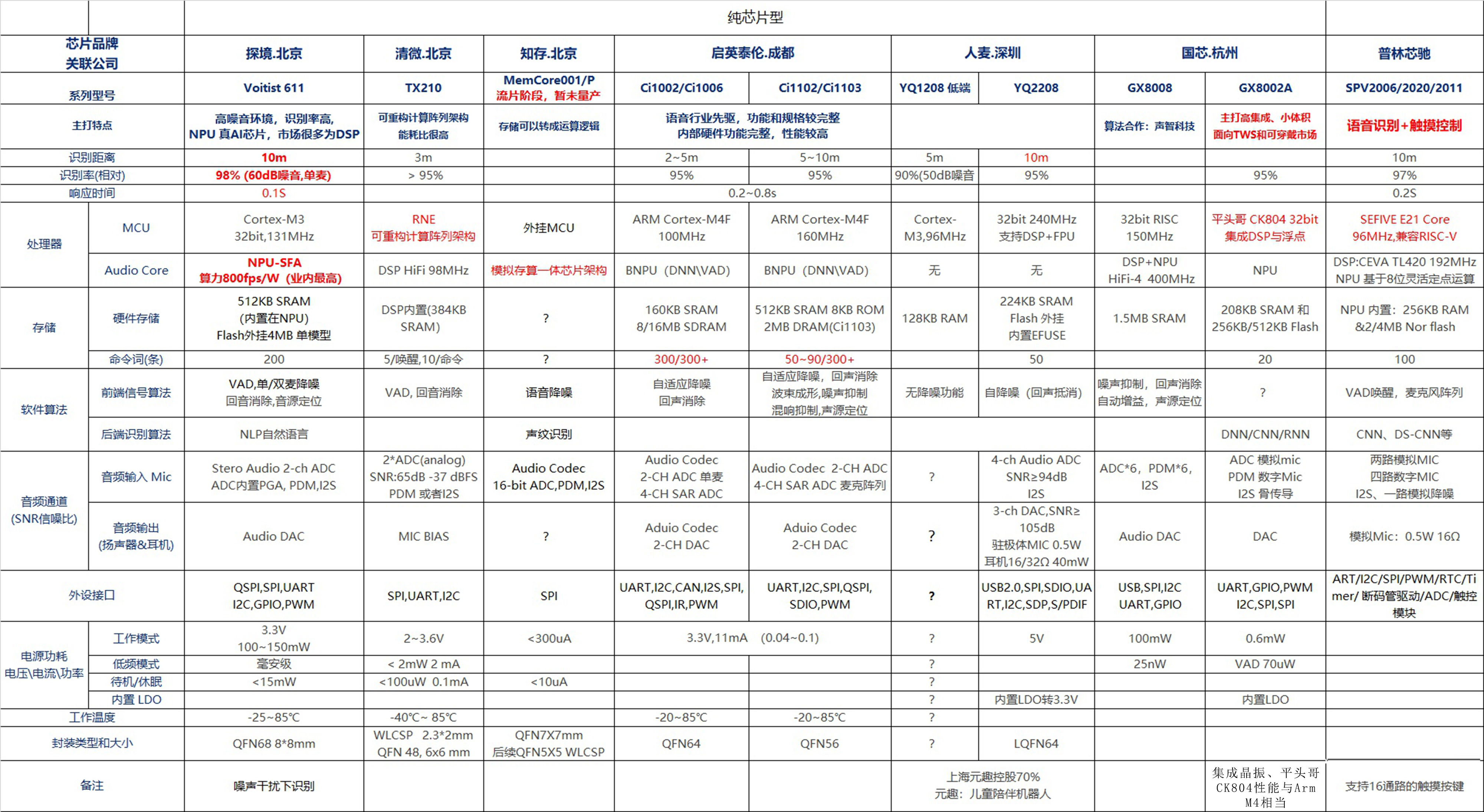
厂商分析:
探境 & 清微 & 知存
三家北京系的公司,在NPU(网络神经处理器)上有各自的技术特点和优势,语音识别的处理能力最优,能耗比很高。其中探境较早实现量产,以及扎实的技术持续优化,在高噪音语音识别率和原厂识别表现上,在市场上一枝独秀。另外还有一家北京公司:承芯卓越,暂未查到资料。
启英 & 人麦
两家是最早一批进入3.0时代的厂商,产品均已迭代至第二代,产品经过几年的市场验证较为成熟,也有一定的客户群体。
杭州国芯
国芯成立于2001年,芯片行业的老兵。业务分为两大块:卫星数字电视方案和AI语音识别方案。语音识别的芯片较多,其中刚推出的GX8002A主打”高集成度和小体积”特点,主攻TWS耳机和可穿戴应用。
普林芯驰:该公司暂时了解不多
总结:
市场角度看,语音识别市场当前还远不成气候,仍然属于比较前言的领域。无论是纯芯片型还是互联网型,各自没有真正意义上你死我活的竞争关系,因为与其争夺现有的小饼干,还不如一起拱成大蛋糕分而食之。增量市场阶段,合作共赢更符合各自利益。
产品角度看,语音识别技术仍然有很大的技术进步空间,实际消费者的体验也有待优化,包括像自然语言、非连续性回音消除、端到端技术应用等。也有人说,语音识别芯片加上无线通讯技术,实现离在线一体,兼顾响应速度和识别灵活度。
产业链角度看,从我整理的国内射频芯片原厂开始,到这篇语音识别,知名的厂商都更多集中在北京和上海,深圳虽然有着发达的电子企业和成熟的芯片供应体系(华强北),但芯片制造等产业配套是比不了北上。而且半导体本身属于长周期的投入,可能也不能兼容快节奏的深圳?
声明:本文原作者为龙洋先生,以上所有内容均已征得龙洋先生同意后转载。

